Language Interaction
- Home
- CRL
- Embodied AI
- Language & Interaction
Conversational AI to enhance/augment machine and human capabilities
The Speech Technology Group (STG) is at the heart of modern artificial intelligence by designing novel algorithms for automatic speech recognition and data-driven dialogue systems enabling the creation of advanced and natural, speech enabled, human-machine interfaces.

Speech Technology group
Design conversional AI to enhance/augment user capabilites
Infrastructure
maintenance
Online
Education
Training &
Support
Remote
meetings
Collaborative
Robots
Health
Care
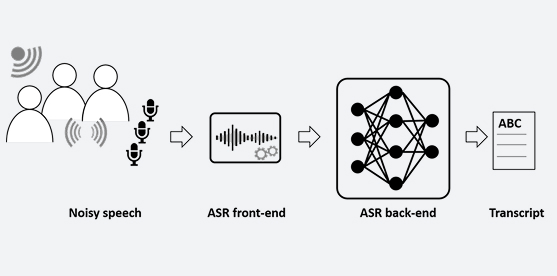
Automatic Speech Recognition
Automatic transcription of speech to text plays a critical role in the human-machine interaction. Background noise, reverberation, competing speakers and natural speech variability across speakers make the task challenging. Toshiba aims to improve the state-of-the-art in automatic speech recognition by combining signal processing and machine learning approaches. Our research focuses on both front-end (signal enhancement) and back-end (acoustic modelling for end-to-end streaming ASR, adaptation of end-to-end models).
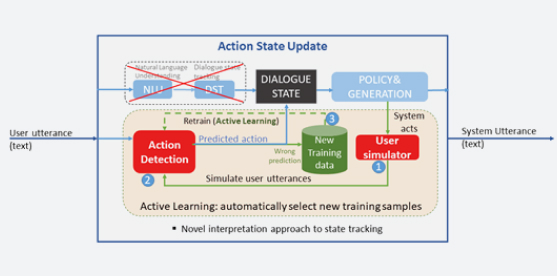
Dialogue Modelling
The Vision & Learning Group (VLG) focuses on learning from interaction in physical environments. Complex and safe manipulation and navigation technology leverage precise 3D geometry and scene understanding in conjunction with strong world-aware action selection frameworks. Learned concepts are effectively transfered to new domains.
Language & Interaction Group Latest Publications
Information contained in news and other announcements is current on the date of posting, but subject to change without notice.
Chao Zhang, Mohan Li, Ignas Budvytis, Stephan Liwicki
Toshiba Europe Ltd
Rudra P.K. Poudel, Harit Pandya, Stephan Liwick, Roberto Cipolla
Cambridge Research Laboratory Toshiba Europe Ltd, UK
Cumulative Attention based streaming transformer ASR with internal language model joint training and rescoring
M. Li, C-T Do and R. Doddipatla
Accepted at the 2023 International Conference on Acoustics, Speech, and Signal Processing (ICASSP 2023), Rhodes Island, Greece, June 2023