Automatic Speech Recognition
- Home
- CRL
- Embodied AI
- Language & Interaction
- Automatic Speech Recognition
Automatic transcription of speech to text plays a critical role in the human-machine interaction. Background noise, reverberation, competing speakers and natural speech variability across speakers make the task challenging. Toshiba aims to improve the state-of-the-art in automatic speech recognition by combining signal processing and machine learning approaches. Our research focuses on both front-end enhancement and back-end acoustic modelling. Some of recent interests include: improving ASR in multiple speaker setting, advancing state-of-the-art and reducing latency for end-to-end ASR using Transformer and Transducer architectures and model adaptation).
Signal Enhancement
Single/multichannel speech enhancement is employed to increase ASR robustness in noisy, reverberant and multi-talker environments. We develop advanced denoising, source separation and speaker diarization techniques for improving recognition accuracy in challenging acoustic conditions.

End-to-end streaming ASR
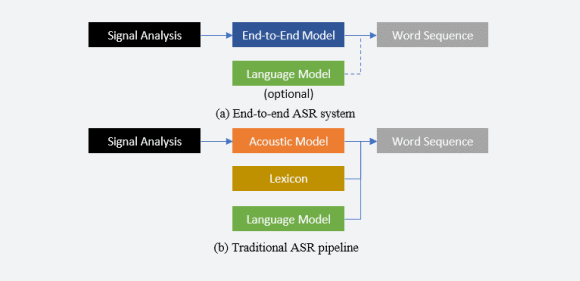
End-to-end ASR models which directly map the input to the output greatly simplify the traditional ASR pipeline which includes an acoustic model, a lexicon and a language model. Our work is to improve end-to-end ASR systems, which includes reducing the computation cost of the model, making the system more suitable for online streaming ASR, or integrating the end-to-end ASR system with various signal enhancement front-end components.
Adaptation of end-to-end ASR
Mismatch between training and test scenarios is common when using ASR system in realistic conditions. Among other robustness methods, adaptation algorithms developed for ASR aim at alleviating this mismatch. Adapting large and complex models, especially deep neural network (DNN)-based models, is challenging with typically a small amount of adaptation (target) data and without explicit supervision. Adaptation methods close the gap in mismatch between training and test and thus try to improve the model performance to unseen settings or environments.
Language & Interaction Group Latest Publications
Information contained in news and other announcements is current on the date of posting, but subject to change without notice.
Rudra P.K. Poudel, Harit Pandya, Stephan Liwick, Roberto Cipolla
Cambridge Research Laboratory Toshiba Europe Ltd, UK
Chao Zhang, Mohan Li, Ignas Budvytis, Stephan Liwicki
Toshiba Europe Ltd
Cumulative Attention based streaming transformer ASR with internal language model joint training and rescoring
M. Li, C-T Do and R. Doddipatla
Accepted at the 2023 International Conference on Acoustics, Speech, and Signal Processing (ICASSP 2023), Rhodes Island, Greece, June 2023